Request Tracer
Microservice communication usually includes multiple requests coming from different places. To separate requests from each other, we use request tracers.
Request tracer is basically 2 functions, one that assigns a unique identifier to each request and other that retrieves that identifier whenever being called. Even though if a request switches microservices few times (for example in an rpc communication request switches between client -> server -> client), that unique identifier should stay the same until the end of the request's journey.
Default Request Tracer
If we don't want to set a complicated request tracer ourselves and want to jump right into the code and start hacking, r4bbit actually makes us covered.
By default, r4bbit provides a request tracer that sets request IDs for each message sent, and the server that actually listens for the messages uses the requestId passed by the client.
So no matter how basic our communication is, we always have the requestIds with our messages.
Most basic rpc communication example
const server = await getServer("amqp://guest:guest@localhost:5672/");
const client = await getClient("amqp://guest:guest@localhost:5672/");
const handler =
(reply: ServerTypes.Reply) => (msg: Record<string, unknown> | string) => {
if (!msg) {
return;
}
reply((msg as { content: string }).content);
};
await server.registerRPCRoute(
{
queueName: "my-queue",
exchangeName: "my-exchange",
routingKey: "my.*",
},
handler
);
await client.publishRPCMessage(
{ message: "OurMessage", nested: { value: "test-Value" } },
{
exchangeName: "my-exchange",
routingKey: "my.routing-key",
replyQueueName: "simple-rpc-reply",
}
);
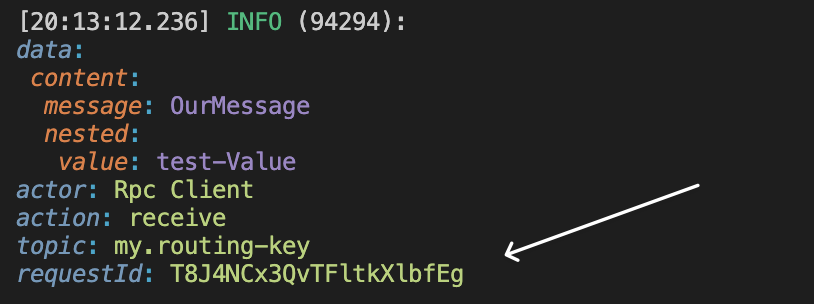
setRequestId and getRequestId
If we have our own request tracing logic, we can easily use it with r4bbit. All we need are 2 functions, r4bbit expects a function that gets the request ID, and sets the request ID.
Lets for our simple example have a global variable that acts like our generated requestId
let testReqId = "test-req-id";
setupR4bbit({
requestTracer: {
getReqId: () => testReqId,
setReqId: (reqId) => {
testReqId = reqId;
},
},
});
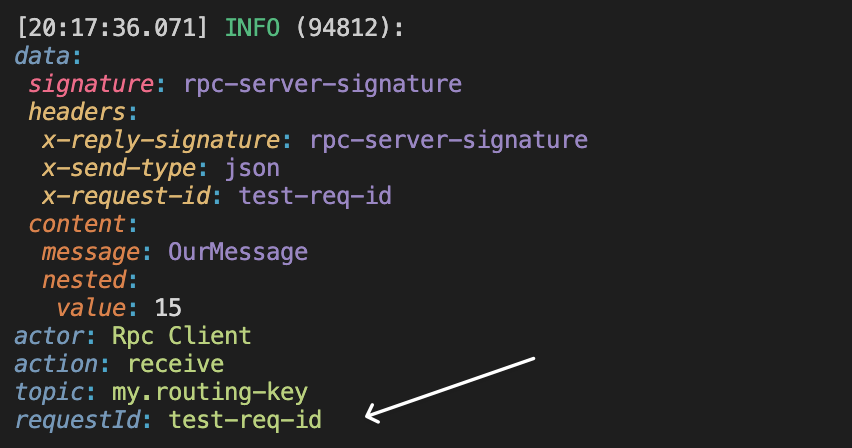
We can easily see that r4bbit called getRequestId and used that one throughout the communication.
Alright, if the only thing we need is getRequestId, why did r4bbit ask for setRequestId too?
Because r4bbit wants the whole journey to be visible to the users, even after the message is received by the server and given to the application, users will probably still log different things.
Sometimes some error messages or sometimes the progress of the operation.
If r4bbit wouldn't be able to pass the requestId to setRequestId method, it would be impossible to track the journey of the message.
Only Giving getRequestId
In an ideal world, we would always pass them both (get and setRequestId functions), but let's say we only have access to getRequestId, what would be then?
const testReqId = "test-req-id";
setupR4bbit({
requestTracer: {
getReqId: () => testReqId,
},
});
Well, not much different than passing both of them , huh? Throughout the RabbitMQ communication with different parties, we don't need setRequestId, the value setRequestId adds, appears only when the message is passed to the application.
Without the setRequestId there is no way to track which request actually belongs to which log.
Only Giving setRequestId
On the other hand, what happens if we only pass the setRequestId?
let testReqId = "test-req-id";
setupR4bbit({
requestTracer: {
setReqId: (reqId) => {
testReqId = reqId;
},
},
});
In that case, r4bbit defines a requestId and uses that requestId throughout the communication, and before passing the result to the application it calls setRequestId and thanks to that, the user would be able to separate the requests